Static Mapping: TNIC Data
Contents
Static Mapping: TNIC Data#
This notebook provides more details on using evomap for deriving static market maps, especially for large input matrices.
Sections#
Loading the Data
Mapping the Data
Exploring the Map
Evaluating the Map
References#
Parts of this example are based on
[1] Matthe, M., Ringel, D. M., Skiera, B. (2022), Mapping Market Structure Evolution. Forthcoming in Marketing Science. https://doi.org/10.1287/mksc.2022.1385
[2] Hoberg, G & Phillips, G. (2016), "Text-Based Network Industries and Endogenous Product Differentiation.", Journal of Political Economy 124 (5), 1423-1465.
Last updated: September 2023
Read the full EvoMap paper here (open access): https://doi.org/10.1287/mksc.2022.1385
Contact: For questions or feedback, please get in touch.
Loading the Data#
First, load all required imports for this demonstration and set the seed to ensure reproducibility.
import pandas as pd
import numpy as np
import os
np.random.seed(123)
For this demonstration, we use a larger sample of the TNIC data also used in [1]. The original data is provided at https://hobergphillips.tuck.dartmouth.edu/.
For more background on TNIC data, see [2]. If you intend to use these data, make sure to cite these authors’ original work!
In the TNIC data, each row corresponds to a single firm-firm pair at a specific point in time. Thus, each firm variable appears twice in each row (once for each firm). We provide these data merged with additional firm information as part of this package.
from evomap.datasets import load_tnic_snapshot
tnic_snapshot = load_tnic_snapshot()
print(tnic_snapshot.keys())
dict_keys(['matrix', 'label', 'cluster', 'size'])
The data consist of four parts:
a symmetric similarity matrix, containing the pairwise relationships among all firms
a label array, containing the name for each firm
cluster assignments, based on pre-clustering of the similarity matrix (obtained via a Community Detection algorithm)
a size array, containing each firm’s market capitalization (*)
(*) Note, that we cannot provide the original market capitalization for licencing reasons, and therefore report a synthetic derivative which is correlated to the firms’ original market capitalization.
# Load each element of the input data
sim_mat = tnic_snapshot['matrix']
labels = tnic_snapshot['label']
clusters = tnic_snapshot['cluster']
market_caps = tnic_snapshot['size']
display("Total number of firms: {0}, such as ..".format(len(labels)))
for label in labels[:5]:
display(" .. " + label)
'Total number of firms: 1092, such as ..'
' .. AMERICAN AIRLINES GROUP INC'
' .. AARONS HOLDINGS COMPANY INC'
' .. ABBOTT LABORATORIES'
' .. AETNA INC'
' .. AIR T INC'
For each (firm, firm) pair these data include a measure of (non-negative) pairwise similarity, ranging between 0 and 1:
display("Smallest similarity: {0}".format(np.min(sim_mat)))
display("Highest similarity: {0}".format(np.max(sim_mat)))
'Smallest similarity: 0.0'
'Highest similarity: 0.8652'
Mapping the Data#
To project these relationships onto the 2D plane, evomap implements a range of popular (static) mapping methods.
Here, we will be using and comparing
Classic Multidimensional Scaling (CMDS),
Sammong Mapping, and
t-SNE
and see how they perform on mapping the TNIC data.
Running these methods follows the typical scikit-learn conventions (fit / transform / fit_transform), for instance
output = CMDS().fit_transform(D)
where D is supposed to be a data matrix (here: a matrix of pairwise distances).
As a result, evomap is fully compatible with other methods implemented in the scikit-learn library.
For instance, you could easily integrate Isomap into the workflow below, and use evomap for preprocessing, plotting, or evaluation. Alternatively, you could use the scikit-learn implementation of t-SNE, which implements a few additional features (such as the Barnes-Hut approximation). For details, see the sklearn.manifold documentation. Further static mapping methods relying on gradient-based optimization routines can easily be integrated into evomap.
Irrespectively of which method you choose, you might need to transform your data according to the method’s specific requirements. Here, we transform the TNIC data (which represent pariwise similarities) into pairwise distances. A straight-forward way to do so is ‘mirroring’ them. Note that the choice of such transformations will have an impact on the resultant maps.
from evomap.preprocessing import sim2diss
D = sim2diss(sim_mat, transformation= 'inverse')
For a start, we use Sammon Mapping (a non-linear variant of Multidimensional Scaling) to project this matrix onto the two-dimensional plane.
from evomap.mapping import Sammon
method = Sammon(
input_type = 'distance', n_iter= 500, verbose = 2)
Y_sammon = method.fit_transform(D)
[SAMMON] Initialization 1/1
[SAMMON] Running Gradient Descent with Backtracking via Halving
[SAMMON] Iteration 50 -- Cost: 0.48 -- Gradient Norm: 840.6893
[SAMMON] Iteration 100 -- Cost: 0.47 -- Gradient Norm: 520.6687
[SAMMON] Iteration 150 -- Cost: 0.46 -- Gradient Norm: 266.8555
[SAMMON] Iteration 200 -- Cost: 0.46 -- Gradient Norm: 118.5507
[SAMMON] Iteration 250 -- Cost: 0.46 -- Gradient Norm: 53.7951
[SAMMON] Iteration 300 -- Cost: 0.46 -- Gradient Norm: 24.8079
[SAMMON] Iteration 350 -- Cost: 0.46 -- Gradient Norm: 11.9917
[SAMMON] Iteration 400 -- Cost: 0.46 -- Gradient Norm: 6.1029
[SAMMON] Iteration 450 -- Cost: 0.46 -- Gradient Norm: 3.2740
[SAMMON] Iteration 500 -- Cost: 0.46 -- Gradient Norm: 1.7979
[SAMMON] Maximum number of iterations reached. Final cost: 0.46
The output Y always consists of an array containing the map coordinates. Y is shaped as (n_samples, n_dims), where ‘n_dims’ usually equals two.
Y_sammon
array([[-4909.17814324, 1470.93232368],
[ 4426.1732782 , -1138.39395038],
[ -642.53598261, 5421.13215712],
...,
[ -77.73716351, -1548.73175579],
[-2260.6731036 , -207.976633 ],
[ -74.57919906, -1523.64017762]])
Exploring the Map#
While one could simply visualize these coordinates in a 2D scatterplot, evomap provides a lot of functionality to create
much richer market maps. All required functions to do so are located within the evomap.printer module.
The baseline function is draw_map:
from evomap.printer import draw_map
draw_map(Y_sammon)
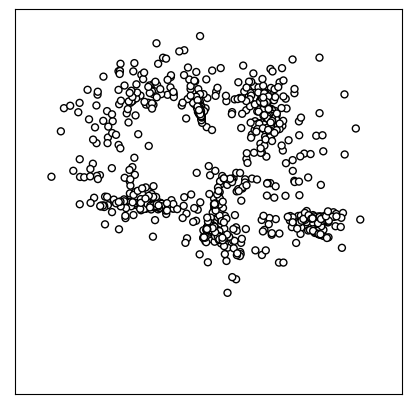
You can change the map’s aesthetics and bind additional data to it via draw_map’s keyword arguments. For instance, if class labels are available (e.g., obtained via clustering or additional metadata), they can be added as colors. Here, we can use SIC codes for coloring:
draw_map(Y_sammon, color = clusters)
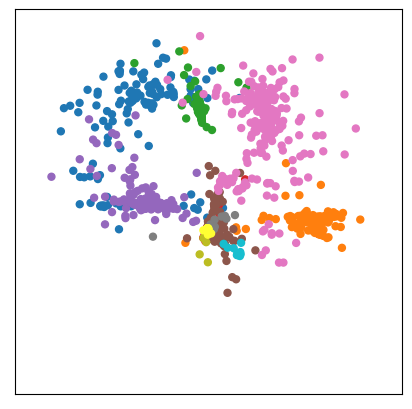
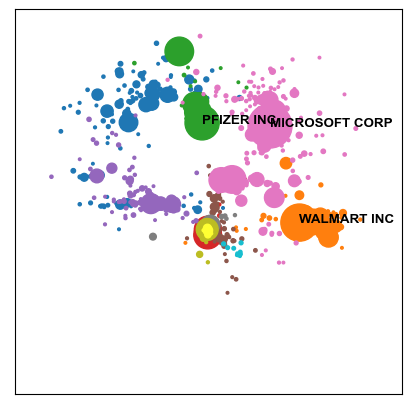
Likewise, one can use additional data to control each point’s size. Here, we are using market capitalization:
draw_map(Y_sammon, color = clusters, size = market_caps)

One can further annotate the map, using labels (e.g., to identify and highlight the positions of specific firms)
draw_map(
Y_sammon,
color = clusters,
label = labels,
size = market_caps,
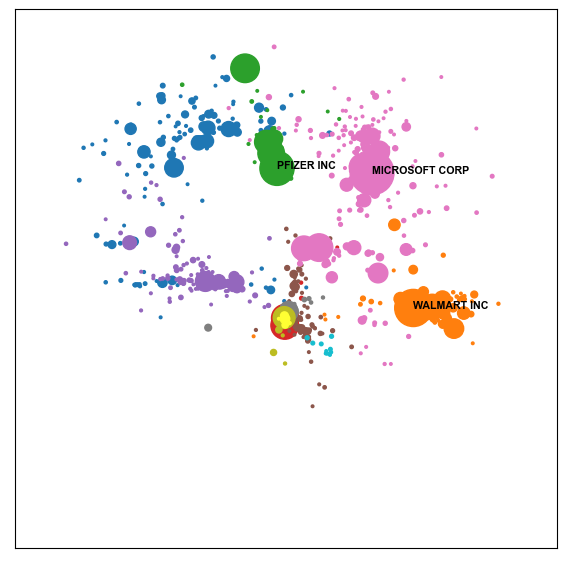
highlighted_labels= ['MICROSOFT CORP', 'WALMART INC', 'PFIZER INC'])
Note that one can also use additional keyword arguments to adjust the plot and its labels further
draw_map(
Y_sammon,
color = clusters,
size = market_caps,
label = labels,
fontdict= {'family': 'Arial', 'size': 8},
highlighted_labels= ['MICROSOFT CORP', 'WALMART INC', 'PFIZER INC'],
fig_size= (7,7))
Evaluating the Map#
Finally, one should always carefully check how good the resultant map represents the input data. To do so, multiple metrics are available from the corresponding module.
A popular choice, especially for larger markets, is the hitrate of nearest-neighbor recovery.
from evomap.metrics import hitrate_score
hitrate_score(
D = sim_mat,
X = Y_sammon,
n_neighbors = 10,
input_format = 'similarity')
0.24532967032967032
Let’s compare the result to two other methods to generate the map.
Classic Multidimensional Scaling (CMDS):
D_norm = D / np.max(D)
from evomap.mapping import MDS
Y_MDS = MDS(
input_type = 'distance',
verbose = 2,
n_iter = 500).fit_transform(D_norm)
[MDS] Running Gradient Descent with Backtracking via Halving
[MDS] Iteration 50 -- Cost: 0.48 -- Gradient Norm: 0.2657
[MDS] Iteration 100 -- Cost: 0.45 -- Gradient Norm: 0.2905
[MDS] Iteration 150 -- Cost: 0.44 -- Gradient Norm: 0.1755
[MDS] Iteration 200 -- Cost: 0.43 -- Gradient Norm: 0.0893
[MDS] Iteration 250 -- Cost: 0.43 -- Gradient Norm: 0.0518
[MDS] Iteration 300 -- Cost: 0.43 -- Gradient Norm: 0.0402
[MDS] Iteration 350 -- Cost: 0.43 -- Gradient Norm: 0.0339
[MDS] Iteration 400 -- Cost: 0.43 -- Gradient Norm: 0.0317
[MDS] Iteration 450 -- Cost: 0.43 -- Gradient Norm: 0.0295
[MDS] Iteration 500 -- Cost: 0.43 -- Gradient Norm: 0.0350
[MDS] Maximum number of iterations reached. Final cost: 0.43
t-distributed Stochastic Neighbor Embedding (t-SNE):
from evomap.mapping import TSNE
Y_tsne = TSNE(input_type= 'distance', verbose = 2).fit_transform(D)
[TSNE] Calculating P matrix ...
[TSNE] Gradient descent with Momentum: 0.5
[TSNE] Iteration 50 -- Cost: 15.51 -- Gradient Norm: 0.0230
[TSNE] Iteration 100 -- Cost: 15.13 -- Gradient Norm: 0.0129
[TSNE] Iteration 150 -- Cost: 15.02 -- Gradient Norm: 0.0084
[TSNE] Iteration 200 -- Cost: 14.97 -- Gradient Norm: 0.0081
[TSNE] Iteration 250 -- Cost: 14.95 -- Gradient Norm: 0.0077
[TSNE] Maximum number of iterations reached. Final cost: 14.95
[TSNE] Gradient descent with Momentum: 0.8
[TSNE] Iteration 288: gradient norm vanished.
Compare how well they perform:
display("MDS Hitrate: {0:.2f}".format(hitrate_score(D = D, X = Y_MDS, n_neighbors=10, input_format = 'dissimilarity')))
display("Sammon Hitrate: {0:.2f}".format(hitrate_score(D = D, X = Y_sammon, n_neighbors=10, input_format = 'dissimilarity')))
display("t-SNE Hitrate: {0:.2f}".format(hitrate_score(D = D, X = Y_tsne, n_neighbors=10, input_format = 'dissimilarity')))
'MDS Hitrate: 0.23'
'Sammon Hitrate: 0.24'
't-SNE Hitrate: 0.50'
These differences in solution quality also become apparent when looking at the map output:
from matplotlib import pyplot as plt
fig, ax = plt.subplots(1,3, figsize = (15, 5))
draw_map(
Y_MDS,
color = clusters,
label = labels,
highlighted_labels=['APPLE INC', 'WALMART INC', 'PFIZER INC'],
size = market_caps,
ax = ax[0])
ax[0].set_title('MDS Solution')
draw_map(
Y_sammon,
label = labels,
highlighted_labels= ['APPLE INC', 'WALMART INC', 'PFIZER INC'],
color = clusters,
size = market_caps,
ax = ax[1])
ax[1].set_title('Sammon Solution')
draw_map(
Y_tsne,
label = labels,
highlighted_labels=['APPLE INC', 'WALMART INC', 'PFIZER INC'],
color = clusters,
size = market_caps,
ax = ax[2])
ax[2].set_title('t-SNEE Solution')
fig
